





AMD 彼は最近、ディスプレイからの負荷を複数のGPUチップに分散するための特許を公開しました。 ゲームシーンは個々のブロックに分割され、木の板に分散されて、ゲームでのシェーディングの使用を改善します。 これには、2レベルのホイルコンテナが使用されます。
AMDは、シェーダーテクノロジーをより有効に活用するためにGPUチップレットを実装するための特許を公開しています
AMDが発行した新しい特許は、AMDが今後数年間で次のレベルのGPUおよびCPUテクノロジーで何をする予定であるかについてのより多くの洞察を開きます。 6月末に、54件の特許出願が提出されたことが明らかになりました。 50を超える公開された特許のどれがAMDの計画で使用されるかは不明です。 特許で説明されているアプリケーションは、今後数年間の会社のアプローチを示しています。
コミュニティメンバー@ETI1120がウェブサイトで気づいたアプリ コンピューターベース、特許番号 US20220207827は、GPUから多くのチップに大量のディスプレイを効率的に渡すための2段階の重要な画像データについて説明しています。 このCPUは、昨年末に米国特許庁に最初に適用されました。
GPU上の画像データが標準的な方法でラスタライズされると、ALUとも呼ばれるシェーダーユニットが同様のタスクを実行し、個々のピクセルに色名を割り当てます。 対照的に、特定のゲームシーンの選択されたピクセルで見つかったテクスチャポリゴンは、ピクセルに直接マッピングされます。 最後に、定式化されたタスクは非定型の原則を維持し、異なるピクセルに配置された他のテクスチャによってのみ異なります。 この方法は、SIMD、または単一命令-複数データと呼ばれます。

現在のほとんどのゲームでは、GPUが生み出したタスクはシェーダーだけではありません。 ただし、代わりに、最初のシェーディングの後に多くの後処理要素が含まれています。 たとえば、GPUが追加するアクションは、ゲーム環境でのアンチエイリアシング、ケラレ、ブロックの防止です。 ただし、レイトレーシングはシェーディングとともに発生するため、新しい計算方法が作成されます。
今日のゲームでグラフィックスを制御するGPUについて話すとき、コンピューターで生成される負荷は、数千のコンピューティングユニットに指数関数的に増加します。
GPU上のゲームでは、このコンピューティング負荷はかなり理想的な方法で数千のコンピューティングユニットになります。 これは、コアを追加するためにアプリケーションを特別に作成する必要があるという点で、プロセッサとは異なります。 CPUスケジューラーはこのアクションを作成し、GPUからの作業を、ビニングとも呼ばれるコンピューティングユニットによって処理されるより理解しやすいタスクに分割します。 ゲームからの画像が表示され、指定された量のピクセルを含む個別のブロックに分割されます。 ブロックはグラフィックプロセッササブユニットによって計算され、そこで同期されて生成されます。 この手順の後、グラフィックカードサブユニットが最終的に使用されるまで、カウントされるのを待っているピクセルがブロックに含まれます。 シェーディングの計算能力、メモリ帯域幅、およびキャッシュサイズが考慮されます。
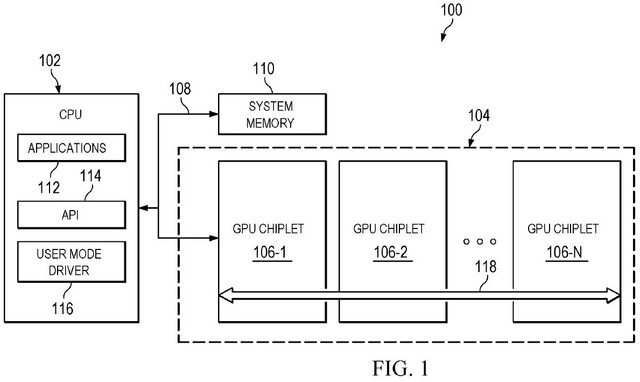
AMDは特許の中で、パーティショニングと結合にはGPUのすべての要素間の包括的で完全なデータ接続が必要であり、これが問題になると述べています。 テンプレートにないデータリンクは待ち時間が長く、プロセスが遅くなります。
CPUは、複数のコアにジョブを送信できるため、このチップレットへの移行が簡単になり、チップレットに非常にアクセスしやすくなっています。 GPUは同じ柔軟性を提供しないため、デュアルコアプリプロセッサに匹敵します。
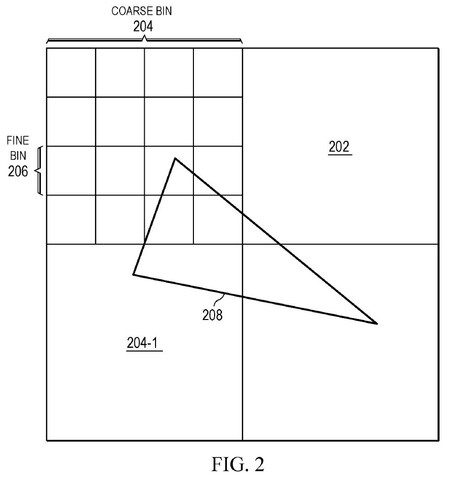
AMDはその必要性を認識し、ラスタライズパイプラインを変更し、CPUと同様に複数のGPU間でタスクを送信することにより、これらの問題に対する回答を提供しようとします。 これには、同社が「ビニングビニング」とも呼ばれる「ビニングビニング」を提供する高度なビニングテクノロジーが必要です。


スーパーアセンブリでは、分割はピクセルごとのブロックに直接処理されるのではなく、2つの別々のフェーズに処理されます。 最初のステップは、方程式を計算し、3D環境を取り、元の画像から2D画像を作成することです。 このステージは頂点シェーダーと呼ばれ、ラスタライズの前に完了します。このプロセスは、GPUの最初のチップではほとんどありません。 終了すると、ゲームシーンはフェードし始め、ギザギザのボックスに進化し、単一のGPUチップで処理されます。 その後、ドットや後処理などの日常的なタスクを開始できます。


AMDがこの新しいプロセスの使用をいつ開始する予定であるか、または承認されるかどうかは不明です。 ただし、より効率的なGPU処理の将来を垣間見ることができます。
ニュースソース: コンピューターベースそしてその オンラインで無料の特許

「流行に敏感な探検家。受賞歴のあるコーヒーマニア。アナリスト。問題解決者。トラブルメーカー。」
More Stories
Apple Sports アプリでは、iOS 18 の iPhone ロック画面でライブスコアを表示できます
APIの保護 – 信頼とイノベーションの鍵
PS5 Proの発表計画とデバイスデザインに関するリーク