





Google 量子 AI
Google は本日、次世代の量子プロセッサである Sycamore での量子誤り訂正のデモンストレーションを発表しました。 Sycamore の冗長性はそれほど魅力的ではありません。ビット数は同じですが、パフォーマンスが向上しています。 そして、量子エラー訂正を取得することは実際にはニュースではありません – 彼らは数年前にそれを機能させることができました.
代わりに、進行の兆候はもう少し微妙です。 前世代のプロセッサでは、キュービットはエラーが発生しやすいため、エラー訂正システムにキュービットを追加すると、訂正の増加よりも多くの問題が発生しました。 この新しい反復では、より多くのキュービットを追加してエラー率を下げることができます。
我々はそれを修正することができます
量子プロセッサの機能単位は量子ビットであり、原子、電子、超伝導エレクトロニクスのブロックなど、量子状態の保存と操作に使用できます。 ビット数が多ければ多いほど、マシンの能力が向上します。 数百に達する頃には、従来のコンピューターでは困難な計算を実行できるようになると考えられています。
つまり、すべての量子ビットが正しく動作すると仮定します。 そして、彼女は一般的にそうではありません。 その結果、より多くの量子ビットを問題に差し引くと、計算が完了する前にエラーが発生する可能性が高くなります。 そのため、現在、400 キュービットを超える量子コンピューターがありますが、400 キュービットすべてを必要とする計算操作を実行しようとすると失敗します。
論理的な誤り訂正量子ビットを作成することは、この問題の解決策として一般的に受け入れられています。 この作成プロセスには、接続された量子ビットのグループ間で量子状態を分散することが含まれます。 (算術論理に関しては、これらすべてのハードウェア キュービットを 1 つのユニットとしてアドレス指定できるため、”論理キュービット” となります。) エラー訂正は、論理キュービットの各メンバーに隣接する追加のキュービットによって有効になります。 これを測定して、論理量子ビットの一部である各量子ビットの状態を推測できます。
ここで、論理量子ビットの一部であるハードウェア量子ビットの 1 つにエラーがある場合、論理量子ビットの情報の一部しか含まれていないという事実は、量子状態が壊れていないことを意味します。 その近傍を測定すると、エラーが明らかになり、定量的な操作でエラーを修正できるようになります。
論理量子ビット専用のハードウェア量子ビットが多いほど、それらはより強力になります。 現在、問題は 2 つだけです。 1 つ目は、余裕のある量子ビットがないことです。 最大数の量子ビットを備えたプロセッサで堅牢なエラー訂正システムを実行すると、計算に 10 未満の量子ビットを使用することが検討されます。 2 つ目の問題は、ハードウェア キュービットのエラー率が高すぎて、いずれも機能しないことです。 論理量子ビットに既存の量子ビットを追加しても、それがより強力になるわけではありません。 一度に多くのエラーが発生して修正できない可能性が高くなります。
同じだけど違う
これらの問題に対する Google の対応は、前世代と同じ数とレイアウトのハードウェア キュービットを備えた新世代の独自の Sycamore プロセッサを構築することでした。 しかし、同社は、個々のキュービットのエラー率を減らして、障害を経験することなくより複雑な操作を実行できるようにすることに重点を置いていました。 これは、エラー修正された論理量子ビットをテストするために Google が使用したデバイスです。
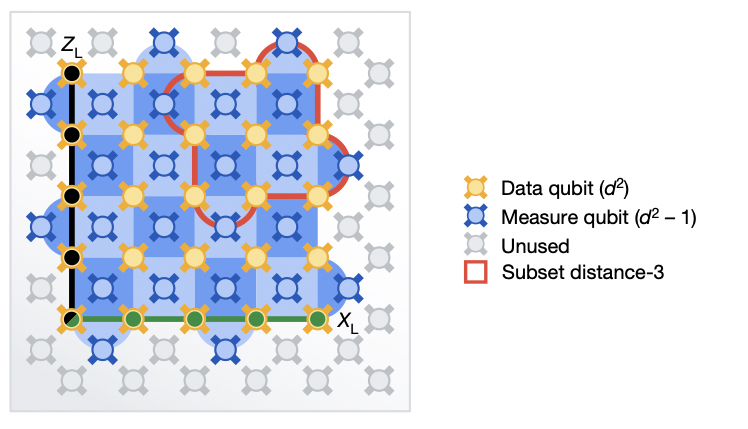
2 つのエラー修正設定。小さいバージョンは赤で強調表示され、大きい設定は青で強調表示されます。 どちらも、データとエラー訂正が並置されています。
Google 量子 AI
この論文では、2 つの異なる方法のテストについて説明します。 どちらの場合も、データは量子ビットの正方形グリッドに格納されました。 これらのそれぞれには、エラー訂正を実行するために測定された隣接するキュービットがありました。 唯一の違いは、グリッドのサイズでした。 1 つの方法では、3 キュービット× 3 キュービットでした。 2つ目は5×5でした。 前者には、合計で 17 個のハードウェア キュービットが必要でした。 後者は 49 キュービットで、およそ 3 倍です。
研究チームは、さまざまなパフォーマンス測定を実施しました。 しかし、基本的な質問は単純でした。エラー率が最も低いのはどの論理量子ビットですか? エラーがハードウェア キュービットで支配的である場合、ハードウェア キュービットの数が 3 倍になり、エラー率が増加することが予想されます。 しかし、Google Performance がハードウェア最適化された量子ビットを十分に変更した場合、より大きく、より堅牢なマッピングによってエラー率が低下するはずです。
より大きな計画が勝ちましたが、それは接戦でした。 全体として、大きい方の論理量子ビットのエラー率は 2.914% でしたが、小さい方の論理ビットでは 3.028% でした。 これは大きな機能ではありませんが、そのような機能が表示されたのはこれが初めてです。 複雑な計算でこれらの論理量子ビットのいずれかを使用するにはエラー率が高すぎることを強調する必要があります。 Google は、ハードウェア キュービットのパフォーマンスをさらに 20% 以上向上させて、大規模な論理キュービットに明確な利点を提供する必要があると見積もっています。
付随するプレス パケットで、Google は、「2025 年以降」に、単一の長寿命の論理量子ビットを操作するという点に到達することを示唆しています。 この時点で、IBM が現在取り組んでいるのと同じ問題の多くに遭遇します。チップに収まるハードウェア キュービットの数は非常に限られているため、非常に多くのチップを単一の計算単位に連結するには、何らかの方法で並べ替える必要があります。 . Google は、そこでソリューションをテストする時期について、日付を明らかにすることを拒否しました。 (IBM は、今年と来年に異なるアプローチをテストする予定であることを示しています。)
つまり、Google のプロセッサの半分近くが 1 つの量子ビットをホストする必要があるエラー修正の 0.11% の改善は、計算の進歩を表すものではありません。 昨日と同じように、暗号化の解読に近づいているわけではありません。 しかし、これは、私たちのキュービットが事態の悪化を回避するのに十分なレベルにすでに達していること、そしてハードウェア キュービットのパフォーマンスを改善する方法に関するアイデアが尽きるずっと前に、私たちがそこに到達したことを示しています。 これは、クリアしなければならない技術的なハードルが量子ビットとは関係のないところに近づいていることを意味します。
ネイチャー、2023年。DOI: 10.1038 / s41586-022-05434-1 (DOIについて)。

「流行に敏感な探検家。受賞歴のあるコーヒーマニア。アナリスト。問題解決者。トラブルメーカー。」
More Stories
Apple Sports アプリでは、iOS 18 の iPhone ロック画面でライブスコアを表示できます
APIの保護 – 信頼とイノベーションの鍵
PS5 Proの発表計画とデバイスデザインに関するリーク